概要:本文使用神经网络完成了一个快速准确的依存语法分析程序,也就是句子的结构。
- introduction:
以前的depenency parser效果很好,但是有几个问题:
- 所用的特征很稀疏,而数据不够训练这些权重。
- 特征都是人工提取的模版,需要专业知识的情况下还经常不全面。
- 计算这些特征十分费时。
作者想出了一个好方法来解决这些问题,其实我觉得这些都是第一个问题带来的。
- Transition-Based Dependency Parsing
先解释什么是Dependency Parsing。依存语法是一种二元非对称关系,一个词A有一个箭头指向另外一个词B, 箭头上通常有标签(label),这些标签表示语法关系,比如主语,同位语等等。箭头连接的两个词有head(高级)和dependent(低级)的区别。而这些箭头称为dependency。本文的箭头是从head到dependent。通常一个句子中加一个假的root,这样每个单词dependent于另一个节点。通常这些依存关系会形成一棵树(连通,非循环,一个根结点)。对于dependency parsing有一个定义是projectivity,叫投影。如果这些箭头没有交叉,则称这个树是projective的。如下图就是这样。
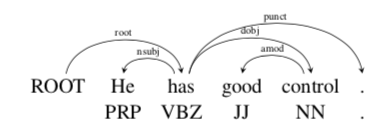
此图是论文中的例子,比如He就dependent于has,因为has说明了he要干嘛,所以has是head。而he是has的名词主语(nominal subjective),就是label。可以看出图中的关系形成了一棵树。
接下来解释什么叫transition-based。依旧是论文的例子。图:
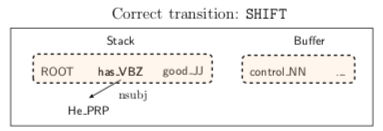
parser有以下几项:
- 一个stack S,root第一个入栈,栈顶靠右,图中栈顶是词good。
- 一个buffer B,第一个元素是在最左边,按照句子的顺序开始。
- 一个放dependency边的集合A。
- transition的集合
在本文中,有如下几种transition:
- LEFT-ARC(l): 往A中增加一条s1到s2的边,label是l
- RIGHT-ARC(l): 往A中增加一条s2到s1的边,label是l
- SHIFT: 把b1移到stack中,前提是buffer的长度大于等于1
对于论文中的例子,有下图:

这样就可以得到句子的dependency 树了,也就是句子的结构。
-
Neural Network Based Parser
本文的目的是通过现有的信息,预测出下一步的transition。首先是所用的模型:
如图所示:
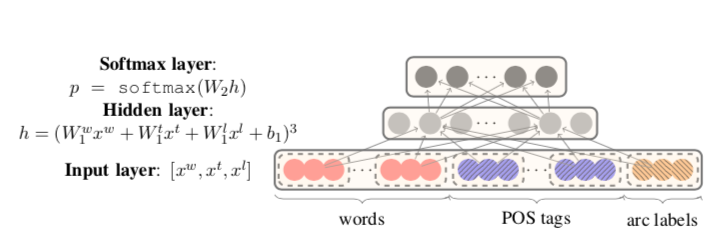
输入由三部分组成,词,词的词性,词的箭头的label,但是全都是embedding的形式。一共选18个词xw:(1)stack和buffer的前3个单词:s1、s2、s3、b1、b2、b3;(2)栈顶两个单词的第一个和第二个最左边/最右边的子单词:lc1(si), rc1(si), lc2(si), rc2(si), i = 1,2。(3)最左边的最左边/最右边的最右边——堆栈上最上面两个单词的大多数子元素:lc1(lc1(si))、rc1(rc1(si))、i = 1,2。xt:使用这18个词的词性标记,xl对应的单词arc的label,不包括Sl堆栈/缓冲区上的那6个单词,有12个,没有的元素用null来代替。embedding的长度是50,直接行向量的形式连接起来,所以输入长度是50*(18+18+12)。
隐藏层的长度是200,由图中公式算出,值得注意的是,公式不仅是进行了线性变换,加了一个三次方,论文中说比起tanh或者sigmoid效果很不错,但是原因说不出,说是有待理论调查。
最终输出层是softmax,有2n+1个transition待选,选出其中可能性最高的。n是总的label的数量。leftarc * n+rightarc * n +shift,共2n+1个transition可选。
最终实验效果很好,速度很快。
具体的训练实验细节和模型评估等请看论文。
感叹:word2vec对于nlp的影响真大。